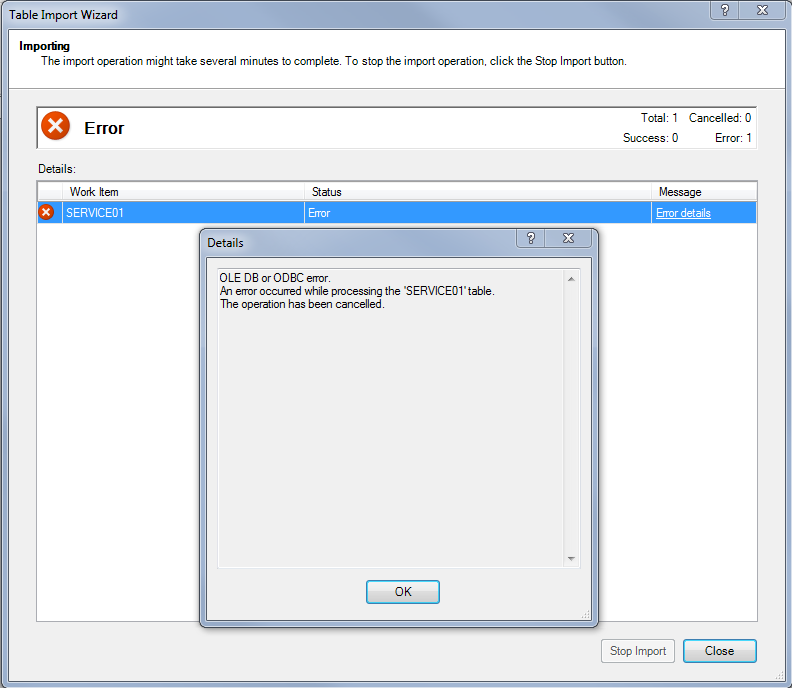
I had to create a new company with Functional Currency being same like existing production. Quite obviously, all Exchange Table IDs are going to be exactly same like in existing production company.
There were around 25 currencies that we have setup. Under normal circumstances, I have to open Multi-Currency Access (Tools -> Setup -> System -> Multi-Currency Access) and select each currency & respective exchange table ID and activate it. 25 times 3 mouse-clicks.
I then decided to tread SQL way. Following is the script which did that 75 clicks in less than a second:
/* MC60100 – Multi-Currency Access Table */
INSERT INTO DYNAMICS..MC60100 (CMPANYID, CURNCYID, INACTIVE)
SELECT [new company id], CURNCYID, 0
FROM DYNAMICS..MC60100
WHERE CMPANYID = [existing company id]
/* MC60200 – Exchange Table ID Access Table */
INSERT INTO DYNAMICS..MC60200 (CMPANYID, EXGTBLID, INACTIVE)
SELECT [new company id], EXGTBLID, 0
FROM DYNAMICS..MC60200
WHERE CMPANYID = [existing company id]
To know the company ID for each of your companies, you can query the table SY01500. Below is that query:
SELECT CMPANYID, INTERID, CMPNYNAM
FROM DYNAMICS..SY01500
ORDER BY CMPANYID
Happy querying.
VAIDY